從Hadoop與MapReduce到淘寶架構 海量數(shù)據(jù)處理的演進與實踐
在當今的信息化社會,數(shù)據(jù)已如潮水般涌現(xiàn),其規(guī)模之大、種類之多、產生速度之快,對傳統(tǒng)數(shù)據(jù)處理技術構成了前所未有的挑戰(zhàn)。海量數(shù)據(jù)處理不僅是技術問題,更是驅動商業(yè)智能、科學研究和日常應用的核心引擎。本文將從經典的Hadoop框架與MapReduce編程模型出發(fā),探討其核心思想,并進一步剖析以淘寶技術架構為代表的現(xiàn)代互聯(lián)網企業(yè)如何演化其數(shù)據(jù)處理與存儲服務體系,以適應瞬息萬變的業(yè)務需求。
一、基石:Hadoop框架與MapReduce模式
海量數(shù)據(jù)處理的早期系統(tǒng)性解決方案,繞不開Apache Hadoop。其核心設計哲學是“移動計算而非數(shù)據(jù)”。面對PB級甚至更龐大的數(shù)據(jù)集,網絡帶寬成為瓶頸,Hadoop通過將計算任務分發(fā)到數(shù)據(jù)所在的節(jié)點,極大地減少了數(shù)據(jù)傳輸開銷。
- HDFS(Hadoop分布式文件系統(tǒng)):作為存儲基石,HDFS將大文件分割成固定大小的數(shù)據(jù)塊(Block),并以多副本形式分布式存儲在集群的普通機器上。其高容錯性和高吞吐量的特性,為上層計算提供了穩(wěn)定的數(shù)據(jù)存儲服務。
- MapReduce編程模型:這是Hadoop最初的計算引擎。其將復雜的數(shù)據(jù)處理任務抽象為兩個核心階段:
- Map(映射):任務被分割并分發(fā)到各數(shù)據(jù)節(jié)點,每個節(jié)點并行處理本地數(shù)據(jù),生成一系列中間鍵值對(Key-Value)。
- Reduce(歸約):將Map階段產生的所有中間結果,按照Key進行排序、分組,并分發(fā)到Reduce節(jié)點進行聚合計算,最終輸出結果。
MapReduce模型簡單而強大,特別適用于批處理任務,如日志分析、網頁索引構建等。它將并行計算、容錯、數(shù)據(jù)分發(fā)等復雜性隱藏于框架之內,讓開發(fā)者能夠專注于業(yè)務邏輯。其“批處理”的天性也帶來了延遲高、迭代計算效率低等局限性。
二、進化:超越批處理的實時化與多樣化
隨著電商、社交等業(yè)務的爆炸式增長,對數(shù)據(jù)處理的實時性、復雜性和靈活性提出了更高要求。以淘寶為代表的互聯(lián)網巨頭,其技術架構經歷了從單一Hadoop體系向混合式、分層化數(shù)據(jù)處理棧的深刻演進。
淘寶的海量數(shù)據(jù)處理與存儲服務架構,可以看作一個多層次、多引擎協(xié)同的生態(tài)系統(tǒng):
- 存儲服務層:統(tǒng)一與分化并存
- 對象存儲(如OSS):用于存儲海量的非結構化或半結構化數(shù)據(jù),如圖片、視頻、前端靜態(tài)資源等,提供高可靠、低成本、無限擴展的存儲能力。
- 分布式文件系統(tǒng):在HDFS基礎上,可能根據(jù)業(yè)務特點進行深度定制或引入新系統(tǒng),以支持更大規(guī)模、更高性能的批處理數(shù)據(jù)存儲。
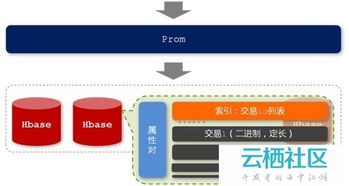
- NoSQL數(shù)據(jù)庫(如HBase、Lindorm):為滿足高并發(fā)、低延遲的在線查詢需求,例如用戶畫像實時查詢、訂單狀態(tài)快速讀取,采用了面向列的分布式數(shù)據(jù)庫,它們能提供毫秒級的隨機讀寫能力。
- NewSQL/分布式關系數(shù)據(jù)庫:對于需要強一致性事務的核心業(yè)務(如交易、庫存),則依賴自研或優(yōu)化的分布式關系型數(shù)據(jù)庫,在保持ACID特性的前提下實現(xiàn)水平擴展。
- 計算服務層:批流一體與場景化引擎
- 批處理引擎:Hadoop MapReduce 逐漸被計算效率更高的 Spark 所補充或替代。Spark利用內存計算和更豐富的算子(RDD、DataFrame),在迭代計算、交互式查詢上性能提升顯著,依然是海量歷史數(shù)據(jù)分析的主力。
- 流處理引擎:為應對實時監(jiān)控、實時推薦、風控等場景,Flink 和 Storm 等流計算框架被廣泛采用。它們能處理無界數(shù)據(jù)流,實現(xiàn)秒級甚至毫秒級的延遲,讓“數(shù)據(jù)價值”隨時間流逝而衰減最小化。淘寶的“實時數(shù)據(jù)平臺”正是構建于此之上。
- 交互式查詢引擎:如 Presto/Trino、Impala 等,提供對海量數(shù)據(jù)的亞秒級到秒級的SQL查詢能力,支持即席分析(Ad-hoc),賦能運營和決策人員。
- 搜索與推薦引擎:這是業(yè)務驅動的特化計算系統(tǒng)。基于倒排索引、向量檢索等技術,構建了能夠處理千億級商品和用戶行為的實時搜索與個性化推薦系統(tǒng)。
- 資源調度與協(xié)調層
- YARN 與 Kubernetes:YARN作為Hadoop2.0的核心,統(tǒng)一管理集群資源,支持多計算框架(MapReduce, Spark, Flink)混部。而現(xiàn)代架構中,容器化技術如Kubernetes正日益成為資源調度和應用部署的新標準,提供更靈活、更高效的資源管理與隔離。
三、架構思想:從工具組合到平臺化服務
淘寶的技術架構演進,清晰地反映了海量數(shù)據(jù)處理領域的發(fā)展趨勢:
- 從單一到融合:從依賴Hadoop批處理一套體系,發(fā)展為“批處理+流處理+交互查詢+事務處理”多模融合的架構,根據(jù)數(shù)據(jù)特性和業(yè)務時效性選擇最佳路徑。
- 從中心化到服務化:數(shù)據(jù)處理能力不再是一個封閉的技術棧,而是以平臺即服務(PaaS)或數(shù)據(jù)即服務(DaaS)的形式提供。內部用戶可以通過標準接口(如SQL、API)便捷地獲取存儲、計算和分析能力,無需關注底層基礎設施的復雜性。
- 從離線到實時:“實時化”成為核心競爭力。數(shù)據(jù)管道從傳統(tǒng)的T+1日級延遲,進化到分鐘級、秒級甚至毫秒級,使得實時決策、實時營銷成為可能。
- 從計算存儲耦合到分離:借鑒“存儲計算分離”的云原生思想,計算資源和存儲資源可以獨立擴展,提升了整體的資源利用率和系統(tǒng)靈活性。
###
從Hadoop MapReduce的開山辟地,到淘寶等互聯(lián)網企業(yè)構建的復雜、高效、實時的數(shù)據(jù)處理生態(tài)系統(tǒng),海量數(shù)據(jù)處理技術的發(fā)展史,是一部不斷應對挑戰(zhàn)、突破極限的創(chuàng)新史。其核心驅動力始終是業(yè)務需求。隨著人工智能的深度融合、云原生技術的普及以及硬件(如存算一體芯片)的革新,海量數(shù)據(jù)處理架構必將朝著更智能、更彈性、更高效的方向持續(xù)演進。理解從經典模式到現(xiàn)代架構的演變邏輯,對于設計下一代數(shù)據(jù)平臺至關重要。
如若轉載,請注明出處:http://www.ktjqovw.cn/product/51.html
更新時間:2026-05-24 23:31:34